0 机器说明
| IP | Role |
| 192.168.1.106 | NameNode、DataNode、NodeManager、ResourceManager |
| 192.168.1.107 | SecondaryNameNode、NodeManager、DataNode |
| 192.168.1.108 | NodeManager、DataNode |
| 192.168.1.106 | HiveServer |
1 打通无密钥
配置HDFS,首先就得把机器之间的无密钥配置上。我们这里为了方便,把机器之间的双向无密钥都配置上。
(1)产生RSA密钥信息
ssh-keygen -t rsa
一路回车,直到产生一个图形结构,此时便产生了RSA的私钥id_rsa和公钥id_rsa.pub,位于/home/user/.ssh目录中。
(2)将所有机器节点的ssh证书公钥拷贝至/home/user/.ssh/authorized_keys文件中,三个机器都一样。
(3)切换到root用户,修改/etc/ssh/sshd_config文件,配置:
RSAAuthentication yesPubkeyAuthentication yesAuthorizedKeysFile .ssh/authorized_keys
(4)重启ssh服务:service sshd restart
(5)使用ssh服务,远程登录:

ssh配置成功。
2 安装Hadoop2.3
将对应的hadoop2.3的tar包解压缩到本地之后,主要就是修改配置文件,文件的路径都在etc/hadoop中,下面列出几个主要的。
(1)core-site.xml
12 3 6hadoop.tmp.dir 4file:/home/sdc/tmp/hadoop-${user.name} 57 10fs.default.name 8hdfs://192.168.1.106:9000 9
(2)hdfs-site.xml
12 3 6dfs.replication 43 57 10dfs.namenode.secondary.http-address 8192.168.1.107:9001 911 14dfs.namenode.name.dir 12file:/home/sdc/dfs/name 1315 18dfs.datanode.data.dir 16file:/home/sdc/dfs/data 1719 22dfs.replication 203 2123 26dfs.webhdfs.enabled 24true 25
(3)hadoop-env.sh
主要是将其中的JAVA_HOME赋值:
export JAVA_HOME=/usr/local/jdk1.6.0_27
(4)mapred-site.xml
12 3 4 7mapreduce.framework.name 5yarn 68 9 12mapreduce.jobhistory.address 10centos1:10020 1113 14 17mapreduce.jobhistory.webapp.address 15centos1:19888 1618 19 22mapreduce.task.io.sort.factor 20100 2123 24 27mapreduce.reduce.shuffle.parallelcopies 2550 2628 31mapred.system.dir 29file:/home/sdc/Data/mr/system 3032 35mapred.local.dir 33file:/home/sdc/Data/mr/local 3436 37 40mapreduce.map.memory.mb 381536 3941 42 45mapreduce.map.java.opts 43-Xmx1024M 4446 47 50mapreduce.reduce.memory.mb 482048 4951 52 55mapreduce.reduce.java.opts 53-Xmx1536M 5456 57 60mapreduce.task.io.sort.mb 58512 59
注意上面的几个内存大小的配置,其中Container的大小一般都要小于所能申请的最大值,否则所运行的Mapreduce任务可能无法运行。
(5)yarn-site.xml
12 3 6yarn.nodemanager.aux-services 4mapreduce_shuffle 57 10yarn.nodemanager.aux-services.mapreduce.shuffle.class 8org.apache.hadoop.mapred.ShuffleHandler 911 14yarn.resourcemanager.address 12centos1:8080 1315 18yarn.resourcemanager.scheduler.address 16centos1:8081 1719 22yarn.resourcemanager.resource-tracker.address 20centos1:8082 2123 24 27yarn.nodemanager.resource.memory-mb 252048 2628 31yarn.nodemanager.remote-app-log-dir 29${hadoop.tmp.dir}/nodemanager/remote 3032 35yarn.nodemanager.log-dirs 33${hadoop.tmp.dir}/nodemanager/logs 3436 39yarn.resourcemanager.admin.address 37centos1:8033 3840 43yarn.resourcemanager.webapp.address 41centos1:8088 42
此外,配置好对应的HADOOP_HOME环境变量之后,将当前hadoop文件发送到所有的节点,在sbin目录中有start-all.sh脚本,启动可见:

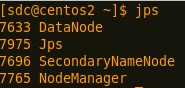

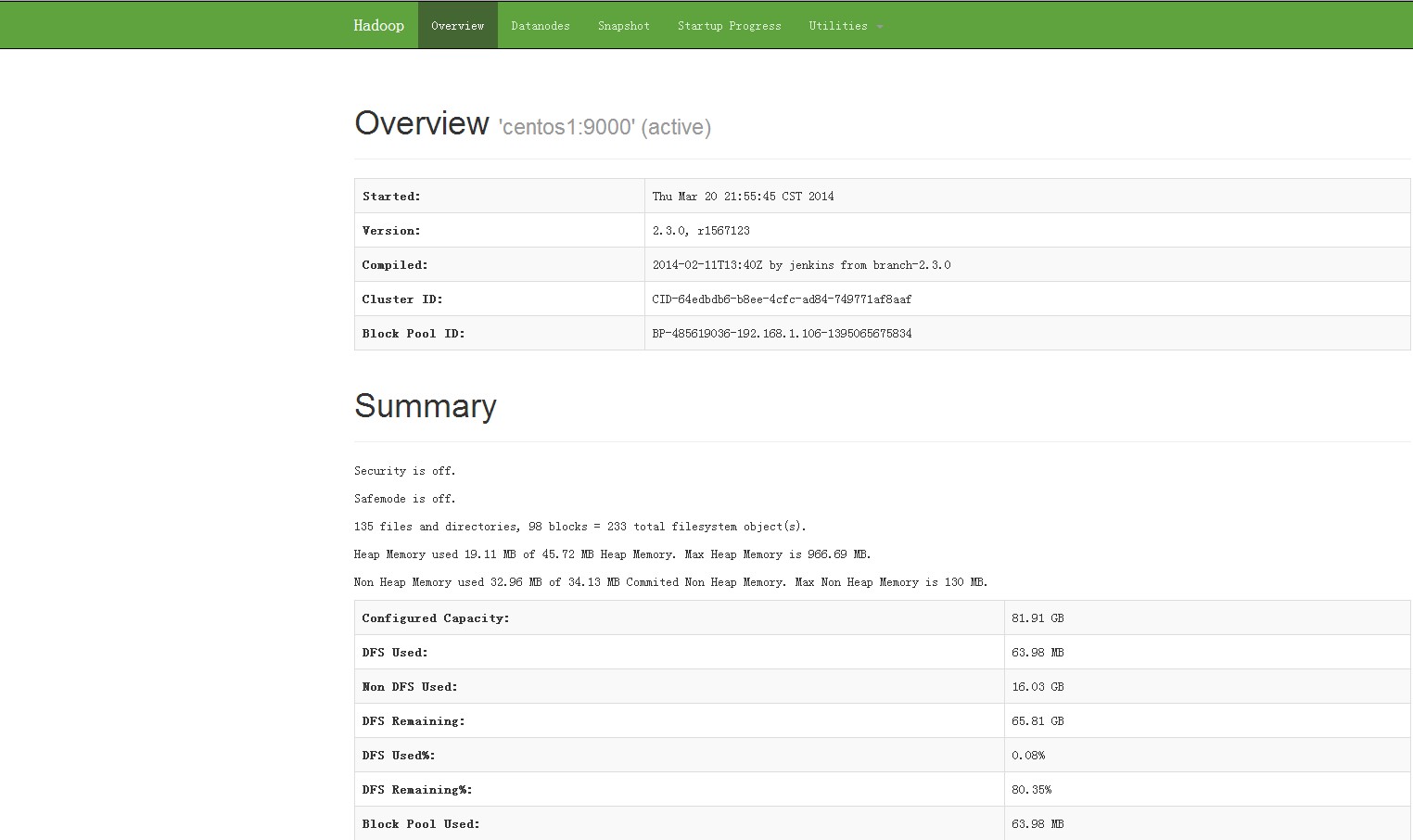
启动完成之后,有如下两个WEB界面:
http://192.168.1.106:8088/cluster

http://192.168.1.106:50070/dfshealth.html
使用最简单的命令检查下HDFS:

3 安装Hive0.12
将Hive的tar包解压缩之后,首先配置下HIVE_HOME的环境变量。然后便是一些配置文件的修改:
(1)hive-env.sh
将其中的HADOOP_HOME变量修改为当前系统变量值。
(2)hive-site.xml
- 修改hive.server2.thrift.sasl.qop属性
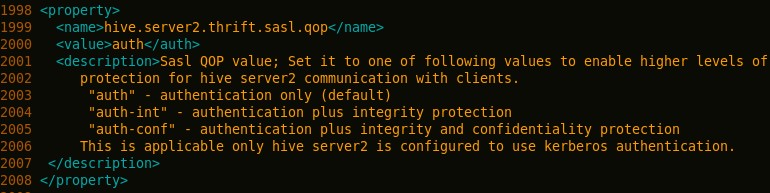
修改为:

- 将hive.metastore.schema.verification对应的值改为false
强制metastore的schema一致性,开启的话会校验在metastore中存储的信息的版本和hive的jar包中的版本一致性,并且关闭自动schema迁移,用户必须手动的升级hive并且迁移schema,关闭的话只会在版本不一致时给出警告。
- 修改hive的元数据存储位置,改为mysql存储:
12 6 7javax.jdo.option.ConnectionURL 3jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8 4JDBC connect string for a JDBC metastore 58 12 13javax.jdo.option.ConnectionDriverName 9com.mysql.jdbc.Driver 10Driver class name for a JDBC metastore 1114 18 19javax.jdo.PersistenceManagerFactoryClass 15org.datanucleus.api.jdo.JDOPersistenceManagerFactory 16class implementing the jdo persistence 1720 24 25javax.jdo.option.DetachAllOnCommit 21true 22detaches all objects from session so that they can be used after transaction is committed 2326 30 31javax.jdo.option.NonTransactionalRead 27true 28reads outside of transactions 2932 36 37javax.jdo.option.ConnectionUserName 33hive 34username to use against metastore database 3538 javax.jdo.option.ConnectionPassword 39123 40password to use against metastore database 41
在bin下启动hive脚本,运行几个hive语句:

4 安装Mysql5.6
见
5 Pi计算实例、Hive表的计算实例运行
在Hadoop的安装目录bin子目录下,执行hadoop自带的示例,pi的计算,命令为:
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0.jar pi 10 10
运行日志为:
1 Number of Maps = 10 2 Samples per Map = 10 3 14/03/20 23:50:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 4 Wrote input for Map #0 5 Wrote input for Map #1 6 Wrote input for Map #2 7 Wrote input for Map #3 8 Wrote input for Map #4 9 Wrote input for Map #510 Wrote input for Map #611 Wrote input for Map #712 Wrote input for Map #813 Wrote input for Map #914 Starting Job15 14/03/20 23:50:06 INFO client.RMProxy: Connecting to ResourceManager at centos1/192.168.1.106:808016 14/03/20 23:50:07 INFO input.FileInputFormat: Total input paths to process : 1017 14/03/20 23:50:07 INFO mapreduce.JobSubmitter: number of splits:1018 14/03/20 23:50:08 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1395323769116_000119 14/03/20 23:50:08 INFO impl.YarnClientImpl: Submitted application application_1395323769116_000120 14/03/20 23:50:08 INFO mapreduce.Job: The url to track the job: http://centos1:8088/proxy/application_1395323769116_0001/21 14/03/20 23:50:08 INFO mapreduce.Job: Running job: job_1395323769116_000122 14/03/20 23:50:18 INFO mapreduce.Job: Job job_1395323769116_0001 running in uber mode : false23 14/03/20 23:50:18 INFO mapreduce.Job: map 0% reduce 0%24 14/03/20 23:52:21 INFO mapreduce.Job: map 10% reduce 0%25 14/03/20 23:52:27 INFO mapreduce.Job: map 20% reduce 0%26 14/03/20 23:52:32 INFO mapreduce.Job: map 30% reduce 0%27 14/03/20 23:52:34 INFO mapreduce.Job: map 40% reduce 0%28 14/03/20 23:52:37 INFO mapreduce.Job: map 50% reduce 0%29 14/03/20 23:52:41 INFO mapreduce.Job: map 60% reduce 0%30 14/03/20 23:52:43 INFO mapreduce.Job: map 70% reduce 0%31 14/03/20 23:52:46 INFO mapreduce.Job: map 80% reduce 0%32 14/03/20 23:52:48 INFO mapreduce.Job: map 90% reduce 0%33 14/03/20 23:52:51 INFO mapreduce.Job: map 100% reduce 0%34 14/03/20 23:52:59 INFO mapreduce.Job: map 100% reduce 100%35 14/03/20 23:53:02 INFO mapreduce.Job: Job job_1395323769116_0001 completed successfully36 14/03/20 23:53:02 INFO mapreduce.Job: Counters: 4937 File System Counters38 FILE: Number of bytes read=22639 FILE: Number of bytes written=94814540 FILE: Number of read operations=041 FILE: Number of large read operations=042 FILE: Number of write operations=043 HDFS: Number of bytes read=267044 HDFS: Number of bytes written=21545 HDFS: Number of read operations=4346 HDFS: Number of large read operations=047 HDFS: Number of write operations=348 Job Counters 49 Launched map tasks=1050 Launched reduce tasks=151 Data-local map tasks=1052 Total time spent by all maps in occupied slots (ms)=57358453 Total time spent by all reduces in occupied slots (ms)=2043654 Total time spent by all map tasks (ms)=28679255 Total time spent by all reduce tasks (ms)=1021856 Total vcore-seconds taken by all map tasks=28679257 Total vcore-seconds taken by all reduce tasks=1021858 Total megabyte-seconds taken by all map tasks=44051251259 Total megabyte-seconds taken by all reduce tasks=2092646460 Map-Reduce Framework61 Map input records=1062 Map output records=2063 Map output bytes=18064 Map output materialized bytes=28065 Input split bytes=149066 Combine input records=067 Combine output records=068 Reduce input groups=269 Reduce shuffle bytes=28070 Reduce input records=2071 Reduce output records=072 Spilled Records=4073 Shuffled Maps =1074 Failed Shuffles=075 Merged Map outputs=1076 GC time elapsed (ms)=71077 CPU time spent (ms)=7180078 Physical memory (bytes) snapshot=653192806479 Virtual memory (bytes) snapshot=1914591641680 Total committed heap usage (bytes)=569675776081 Shuffle Errors82 BAD_ID=083 CONNECTION=084 IO_ERROR=085 WRONG_LENGTH=086 WRONG_MAP=087 WRONG_REDUCE=088 File Input Format Counters 89 Bytes Read=118090 File Output Format Counters 91 Bytes Written=9792 Job Finished in 175.556 seconds93 Estimated value of Pi is 3.20000000000000000000
如果运行不起来,那说明HDFS的配置有问题啊!
Hive中执行count等语句,可以触发mapduce任务:
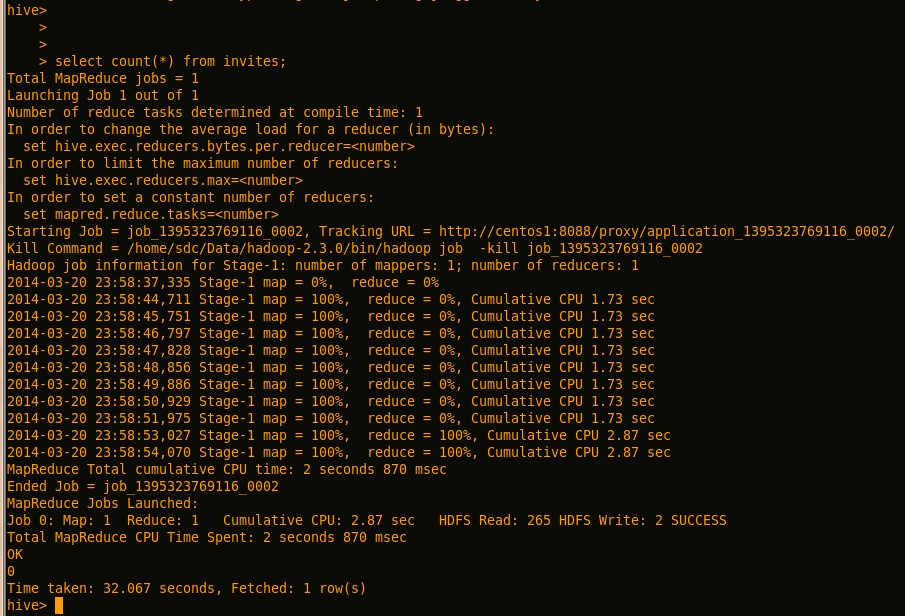
如果运行的时候出现类似于如下的错误:
Error in metadata: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
说明元数据存储有问题,可能是以下两方面的原因:
(1)HDFS的元数据存储有问题:
$HADOOP_HOME/bin/hadoop fs -mkdir /tmp $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
(2)Mysql的授权有问题:
在mysql中执行如下命令,其实就是给Mysql中的Hive数据库赋权
grant all on db.* to hive@'%' identified by '密码';(使用户可以远程连接Mysql)grant all on db.* to hive@'localhost' identified by '密码';(使用户可以本地连接Mysql)flush privileges;
具体哪方面的原因,可以查看hive的日志。
-------------------------------------------------------------------------------
如果您看了本篇博客,觉得对您有所收获,请点击右下角的 [推荐]
如果您想转载本博客,请注明出处
如果您对本文有意见或者建议,欢迎留言
感谢您的阅读,请关注我的后续博客